Trying out C++26 executors
Back in 2020 I did a remote talk at CppCon about my work on making Stellaris boot up much faster. I later brought similar improvements to Hearts of Iron IV and Europa Universalis IV (although I’m afraid the latter was never pushed to the live branch, you have to opt-in to a beta version). They key to those improvement was, of course, concurrency: put stuff to load in the background if it’s not needed upfront, and use multiple threads to do the work when possible.
One of my goals this year has been to get into graphics programming, using my spare time between clients to play with OpenGL, raylib, SDL3_GPU and more recently, Vulkan. My latest project is to build a Vulkan renderer step by step, and as it grew so did the startup times. It’s still only a matter of seconds (even in Debug) yet I thought it would be interesting to take advantage of Vulkan’s strong push towards multithreaded graphics to get some prototype going, and use the lessons learned to eventually make a proper efficient asset loader.
And so I got thinking, while I could definitely do it with some combination of C+11 future/promise/async and C++17 std::execution::par_unseq loops, or use TBB (which was my go-to on production games), I figured I should give the upcoming C++26 executors a shot.
The use case
My project currently has only a few assets to load, but they each take some measure of CPU time:
- The mesh drawing pipeline uses 2 shaders (vertex + fragment) that need to be compiled from GLSL to SPIRV
- The test mesh itself uses PNG for textures, which need to be decompressed to RGBA before they can uploaded to VRAM
Of course, a production game would usually have a baking process to avoid both of these caveats, making sure to ship pre-compiled SPIRV shader blobs and assets optimized with textures that can be directly uploaded to the GPU, but in my experience during development you definitely want your asset loader to able to handle unoptimized assets and text shaders to be able to iterate quickly.
Originally, the whole process was all serially done on the main thread, but obviously we can improve on that:
- Shaders can be compiled in parallel, and the pipeline that uses them can itself be created while the assets are being loaded on another thread as long as the shader binding layout used has been initialized.
- A GLTF asset can be parsed on a dedicated thread, and then we can have a task repacking/uploading vertices, and another that handles the textures upload, and it can itself break down the PNG texture decompression on multiple threads.
Here’s a diagram for reference:
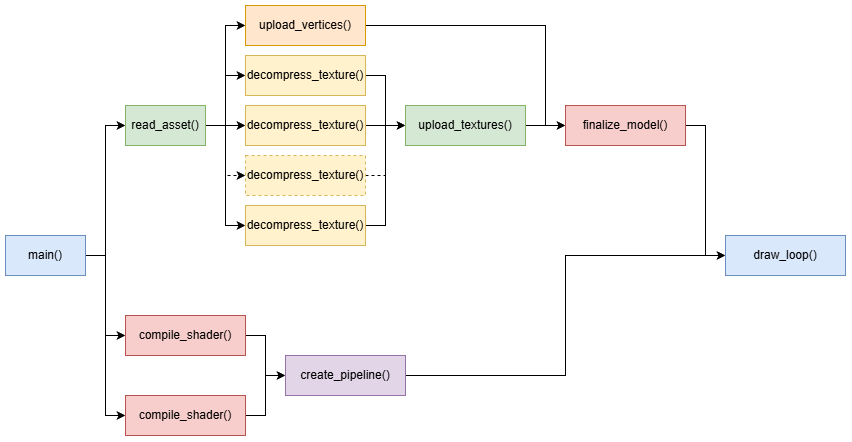
If done correctly, most of those tasks can be done in parallel assuming our machine has enough cores available.
The classic way
To get a frame of reference (and proof that the idea is sound), I ran a quick vcpkg install tbb (you guys are using a package manager, right?) and implemented it in the way I’m familiar with. I picked TBB over std::execution_par_unseq and std::async because I am quite familiar with TBB and I know all jobs are guaranteed to run on the same thread pool (unlike std::async which might create new thread) and also because it provides the very convenient tbb::task_scheduler_observer which can used to ensure the worker threads will properly register in Optick (I had to hack around a bit to make that work with stdexec).
Here’s a shortened version of what it looks like:
Pipeline create_pipeline( vk::Device device, vk::DescriptorSetLayout layout )
{
vk::raii::ShaderModule vertex_shader;
vk::raii::ShaderModule fragment_shader;
tbb::parallel_invoke(
[ & ] { vertex_shader = compile_shader( device, "mesh.vs", VK_SHADER_STAGE_VERTEX_BIT ); },
[ & ] { fragment_shader = compile_shader( device, "mesh.fs", VK_SHADER_STAGE_FRAGMENT_BIT ); }
);
/* ... */
return make_pipeline( device, layout, vertex_shader, fragment_shader );
}
void MeshLoadJob::decompress_textures()
{
tbb::parallel_for(
size_t( 0 ),
_textures.size(),
[ & ]( size_t index )
{
_textures[ index ].decompress();
} );
}
Model load_model( vk::Device device, TexManager& tex_manager )
{
MeshLoadJob job( device, tex_manager, "model.glb" );
job.parse();
tbb::parallel_invoke( [ & ]() { job.upload_vertices(); },
[ & ]
{
job.decompress_textures();
job.upload_textures();
} );
return job.finalize();
}
void main()
{
/* Init Vulkan... */
Pipeline pipeline;
Model model;
tbb::parallel_invoke(
[ & ] { pipeline = create_pipeline( device, layout ); },
[ & ] { model = load_model( device, tex_manager ); } );
/* Draw loop... */
}
And here’s a profile capture of the result:
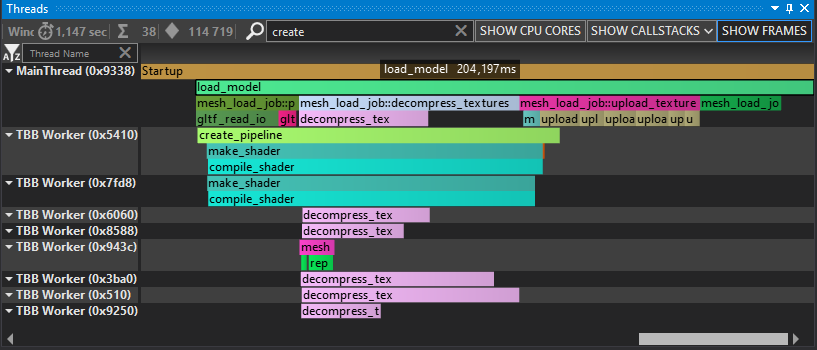
This is about as good as we could expect, TBB uses 9 work thread (including the main one) to decompress 6 textures, upload vertices and compile 2 shaders. Technically we could further optimize it because the RGB to RGBA conversion done by SDL in upload_image() is still taking about 50ms of mostly CPU crunch but this is good enough to illustrate our gains here. The whole process takes about 200 ms in Release and 900 ms in Debug (mostly bound by how slow the shader compiler is in Debug, but mixing Debug/Release packages is a topic for another day) down from maybe 4-5 seconds when iterating with the Debug build.
Now, let’s see how executors will compare.
The C++26 way
For this experiment, I downloaded NVIDIA’s stdexec which is the reference implementation used for the executor’s paper. I initially used the version from vcpkg, but I realized the package is outdated by over a year so I switched to the main branch as of this post’s date. Then, I focused on solving the asset loading part, thinking that once I got it going for that I could compose it further to add the shader compilation.
Here’s how it looks like:
Model load_model( vk::Device device, TexManager& tex_manager )
{
MeshLoadJob job( device, tex_manager, "model.glb" );
using namespace stdexec;
auto parse_ask = split( scheduler.schedule() | then( [ & ] { job.parse(); } ) );
sync_wait(
when_all( parse_ask | then( [ & ] { job.upload_vertices(); } ),
parse_ask
| let_value(
[ & ]
{
return just()
| bulk( stdexec::par_unseq, job.get_texture_count(),
[ & ]( int i ) { job.decompress_texture( i ); } );
} )
| then( [ & ] { job.upload_textures(); } ) )
| then( [ & ] { job.finalize(); } ) );
return job.get_result();
}
It works and we can describe the whole job in one go, but sadly the practical result didn’t look overwhelming:
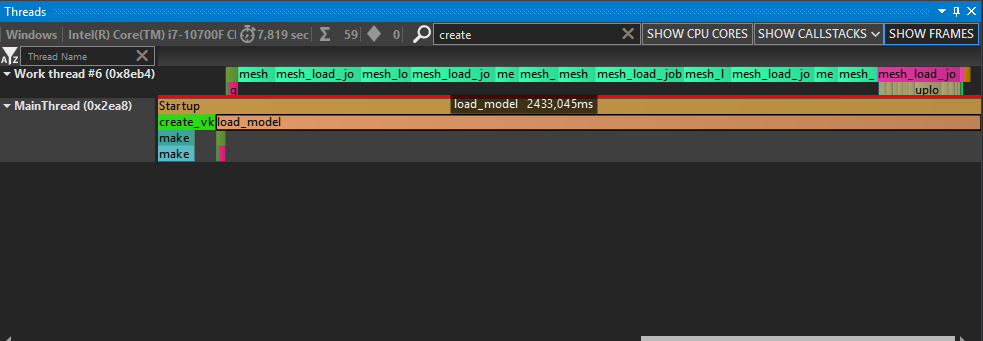
As you can see, the bulk() part was actually executed in serial, and no amount of stdexec::par_unseq seemed to affect it. This is also quite verbose. The let_value() wrapper is necessary to make sure the count passed to bulk() is only evaluated once the parse() is done and not immediately, else it gets 0 because we haven’t run the parser yet (and so we skip decompression and crash later cause the uncompressed textures aren’t there). Needing to do just() | bulk() and schedule() | then() all the time is also adding extra noise.
Debugging why my bulk() was not actually ran in parallel proved fruitless, lost in thousand character long template argument lists and compile-time evaluation that I couldn’t put any breakpoint on to see where the branches go wrong.
Worse, I only caught the issue because I am always double checking the profiler. I really don’t like the idea that stdexec::par_unseq seems to only be a suggestion, meaning it can result in cases where it seems to work but the performance is actually terrible because everything is run in serial. I’d much prefer a compile error if my task construction somehow breaks a constraint required to parallelize.
After a while I was saved by my ex-colleague Jérémy Demeule who suggested I added a continues_on() call to make sure the executors didn’t lose track of where they’re supposed to execute and go back to the original thread pool scheduler:
let_value(
[ & ]
{
return just()
| continues_on( scheduler ) // remind the executor where we are...
| bulk( stdexec::par_unseq, job.get_texture_count(),
[ & ]( int i ) { job.decompress_texture( i ); } );
} )
This way we get proper multithreading:
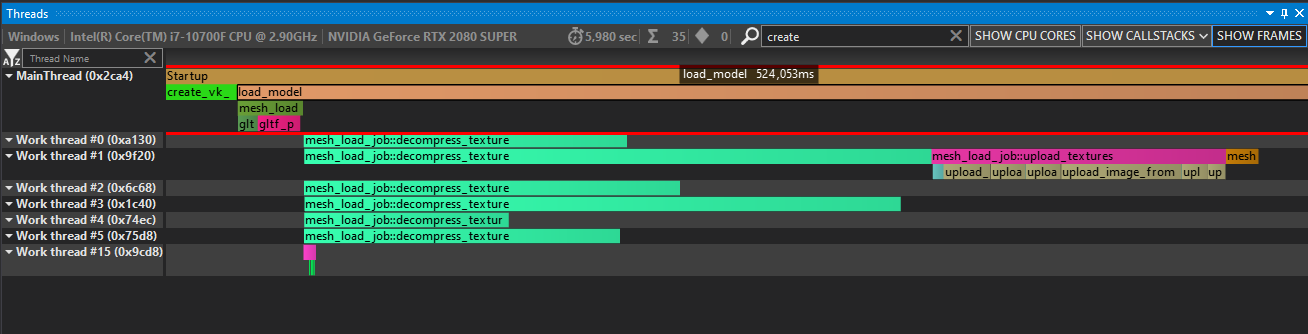
I’m not sure if this is an intended part of the spec or a bug in stdexec implementation but I hope it’s the latter because else I can see tripping a lot of people silently (remember: it doesn’t fail to compile, it just executes on the default serial scheduler).
In the end I elected to simplify the code by first running the parse() part directly, then building a task graph:
Model load_model( vk::Device device, TexManager& tex_manager )
{
MeshLoadJob job( device, tex_manager, "model.glb" );
using namespace stdexec;
job.parse();
sync_wait( when_all( scheduler.schedule() | then( [ & ] { job.upload_vertices(); } ),
scheduler.schedule()
| bulk( stdexec::par_unseq, job.get_texture_count(),
[ & ]( int i ) { job.decompress_texture( i ); } )
| then( [ & ] { job.upload_textures(); } ) )
| then( [ & ] { job.finalize(); } ) );
return job.get_result();
}
Conclusion
While I like the pipe declarative syntax I worry that the potential footguns and extra verbosity will turn off potential users. As with a lot of recent C++ libraries, the library relies on a lot of template/constexpr magic going right, and leaves you in a pretty bad spot when it doesn’t.
The amount of extra just() and continues_on() and then() needing to start a task chain in general feels like a bit too much and could benefit from some trimming/shortcuts. Especially since introducing any form of runtime dependency in the chain already requires some amount of let_value() wrapping. This is probably less of an issue when describing a networking processing chain or a single async disk load, but handling dynamic splits and joins isn’t nearly as nice.
I also would like to see some form wait_steal rather than only sync_wait. Feels like a waste that invoking the whole thing puts the caller to sleep rather than have them contribute to the work. I haven’t tried how it behaves if called from a work thread on the same scheduler, hopefully it doesn’t just keep it idle while it waits, else I could see it starving itself out.
I haven’t mentioned the impact on compile times but according to MSVC’s build insights adding only this one execution added a whopping 5s build time, mostly in template instantiation so even modules won’t save this one.
Finally, I haven’t mentioned that a big feature of C++26 execution is the ability to pass parameters between tasks and automatically handle their lifecycle. It looks quite nice for single/one shot cases, but you’d notice for this case I elected to keep all the shared data as an external struct on the stack captured by reference rather than having to deal with how to handle data passing between and splits and joins.
In the end, I know we’ve been talking about executors for over a decade, and the people working on it have certainly done an extremely smart job that I couldn’t pull off myself. Yet, I wonder: is it the right way to add such a big thing to the standard? Wouldn’t that energy be better spent in making a widely used and adopted library (like Boost in its time), and then standardize it once we had enough real-world experience in live projects? After all that’s how we got unique_ptr, optional, tuple, any, span, variant and even expected.
To quote the project’s page (emphasis mine):
stdexecis experimental in nature and subject to change without warning. The authors and NVIDIA do not guarantee that this code is fit for any purpose whatsoever.
This doesn’t make me feel like something that should to be required in every C++ compiler starting next year. And obviously with that in mind I’ll keep this as an experiment on a branch and stick with TBB until then.